
2023
He, R., Lieder, F.
What are the mechanisms underlying metacognitive learning?
In July 2023 (inproceedings) Accepted
Singhi, N., Mohnert, F., Prystawski, B., Lieder, F.
Toward a normative theory of (self-)management by goal-setting
Proceedings of the Annual Meeting of the Cognitive Science Society, Annual Meeting of the Cognitive Science Society, July 2023 (conference) Accepted
Srinivas, S., He, R., Lieder, F.
Learning planning strategies without feedback
July 2023 (conference) Accepted
Maier, M., Cheung, V., Bartos, F., Lieder, F.
Learning from Consequences Shapes Reliance on Moral Rules vs. Cost-Benefit Reasoning
April 2023 (article) Submitted
Becker, F., Wirzberger, M., Pammer-Schindler, V., Srinivas, S., Lieder, F.
Systematic metacognitive reflection helps people discover far-sighted decision strategies: a process-tracing experiment
Judgment and Decision Making, March 2023 (article) Accepted
Amo, V., Prentice, M., Lieder, F.
Formative assessment of the InsightApp: An ecological momentary intervention that helps people develop (meta-)cognitive skills to cope with stressful situations and difficult emotions
JMIR Formative Research, March 2023 (article) Accepted
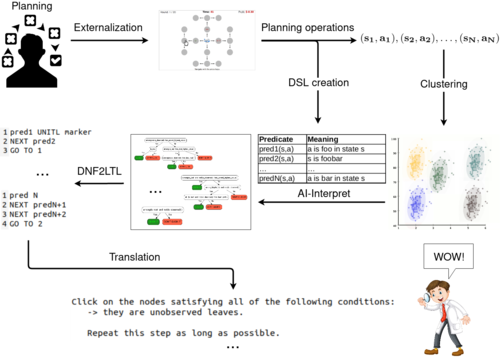
Skirzynski, J., Jain, Y. R., Lieder, F.
Automatic discovery and description of human planning strategies
Behavior Research Methods, January 2023 (article) Accepted
2022
Wirzberger, M., Lado, A., Prentice, M., Oreshnikov, I., Passy, J., Stock, A., Lieder, F.
Can we improve self-regulation during computer-based work with optimal feedback?
Behaviour & Information Technology, November 2022 (article) Submitted
Lieder, F., Prentice, M.
Life Improvement Science
In Encyclopedia of Quality of Life and Well-Being Research, Springer, November 2022 (inbook)
Lieder, F.
Which research topics are most important for promoting flourishing?
In Global Conference on Human Flourishing, Templeton World Charity Foundation, November 2022 (inproceedings) Accepted
He, R., Lieder, F.
Learning-induced changes in people’s planning strategies
November 2022 (article) Submitted
Lieder, F., Chen, P., Prentice, M., Amo, V., Tošić, M.
A mathematical principle for the gamification of behavior change
JMIR Preprints, JMIR Publications, October 2022 (article)
Lieder, F., Chen, P., Stojcheski, J., Consul, S., Pammer-Schindler, V.
A cautionary tale about AI-generated goal suggestions
Mensch und Computer, September 2022 (article) Accepted
Consul, S., Stojcheski, J., Lieder, F.
Leveraging AI for effective to-do list gamification
In 5th international workshop Gam-R – Gamification Reloaded, September 2022 (inproceedings) Accepted
Jähnichen, S., Weber, F., Prentice, M., Lieder, F.
Does deliberate prospection help students set better goals?
KogWis 2022 "Understanding Minds", September 2022 (poster) Accepted
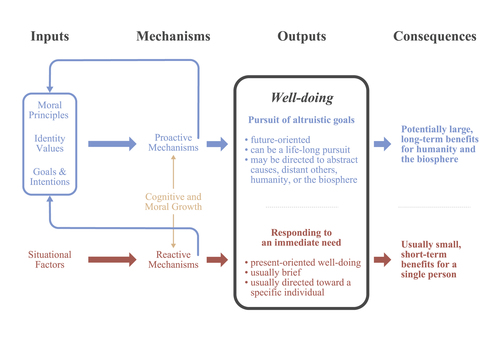
Lieder, F., Prentice, M., Corwin-Renner, E.
An interdisciplinary synthesis of research on understanding and promoting well-doing
Social and Personality Psychology Compass, e12704, August 2022 (article)
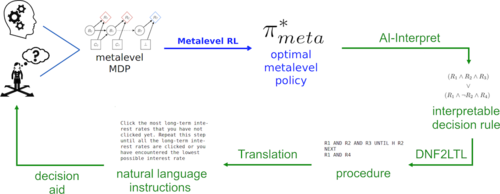
Becker, F., Skirzyński, J., van Opheusden, B., Lieder, F.
Boosting human decision-making with AI-generated decision aids
Computational Brain & Behavior, 5(4):467-490, July 2022 (article)
Mehta, A., Jain, Y. R., Kemtur, A., Stojcheski, J., Consul, S., Tosic, M., Lieder, F.
Leveraging machine learning to automatically derive robust decision strategies from imperfect models of the real world
Computational Brain & Behavior, Springer Nature, June 2022 (article)
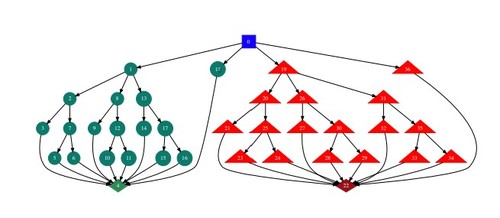
Consul, S., Heindrich, L., Stojcheski, J., Lieder, F.
Improving Human Decision-Making by Discovering Efficient Strategies for Hierarchical Planning
Computational Brain & Behavior, 5(1), Springer, April 2022 (article)
Callaway, F., Opheusden, B. V., Gul, S., Das, P., Krueger, P. M., Griffiths, T. L., Lieder, F.
Rational use of cognitive resources in human planning
Nature Human Behaviour, April 2022 (article) Accepted
Pauly, R., Heindrich, L., Amo, V., Lieder, F.
What to learn next? Aligning gamification rewards to long-term goals using reinforcement learning
March 2022 (article) Accepted
Callaway, F., Jain, Y. R., Opheusden, B. V., Das, P., Iwama, G., Gul, S., Krueger, P. M., Becker, F., Griffiths, T. L., Lieder, F.
Leveraging artificial intelligence to improve people’s planning strategies
119(12), PNAS, March 2022 (article)
Amo, V., Prentice, M., Lieder, F.
Promoting value-congruent action by supporting effective metacognitive emotion-regulation strategies with a gamified app
Society for Personality and Social Psychology (SPSP) Annual Convention 2022, San Francisco, USA, Society for Personality and Social Psychology (SPSP) Annual Convention 2022, February 2022 (conference)
Prentice, M., Gonzalez Cruz, H., Lieder, F.
Evaluating Life Reflection Techniques to Help People Select Virtuous Life Goals
Integrating Research on Character and Virtues: 10 Years of Impact, Oriel College, Oxford, Integrating Research on Character and Virtues: 10 Years of Impact, January 2022 (conference) Accepted
Krueger, P., Callaway, F., Gul, S., Griffiths, T., Lieder, F.
Discovering Rational Heuristics for Risky Choice
PsyArXiv Preprints, January 2022 (article) Submitted
Jain, Y. R., Callaway, F., Griffiths, T. L., Dayan, P., He, R., Krueger, P. M., Lieder, F.
A Computational Process-Tracing Method for Measuring People’s Planning Strategies and How They Change Over Time
Behavior Research Methods, 2022 (article) In press
2021
Becker, F., Lieder, F.
Promoting metacognitive learning through systematic reflection
Workshop on Metacognition in the Age of AI. Thirty-fifth Conference on Neural Information Processing Systems, Thirty-fifth Conference on Neural Information Processing Systems, December 2021 (conference) Accepted
He, R., Jain, Y. R., Lieder, F.
Have I done enough planning or should I plan more?
Workshop on Metacognition in the Age of AI. Thirty-fifth Conference on Neural Information Processing Systems, Long Paper, Workshop on Metacognition in the Age of AI. Thirty-fifth Conference on Neural Information Processing Systems, December 2021 (conference) Accepted
Prystawski, B., Mohnert, F., Tošić, M., Lieder, F.
Resource-Rational Models of Human Goal Pursuit
Topics in Cognitive Science, Online, Wiley Online Library, August 2021 (article)
Becker, F., Skirzynski, J. M., van Opheusden, B., Lieder, F.
Encouraging far-sightedness with automatically generated descriptions of optimal planning strategies: Potentials and Limitations
Proceedings of the 43rd Annual Meeting of the Cognitive Science Society, Online, Annual Meeting of the Cognitive Science Society, July 2021 (conference)
Frederic Becker, , Lieder, F.
Promoting metacognitive learning through systematic reflection
The first edition of Life Improvement Science Conference, June 2021 (poster)
Teo, J., Pauly, R., Heindrich, L., Amo, V., Lieder, F.
Leveraging AI to support the self-directed learning of disadvantaged youth in developing countries
The first Life Improvement Science Conference, Tübingen, Germany, The first Life Improvement Science Conference, June 2021 (conference) Accepted
Heindrich, L., Consul, S., Stojcheski, J., Lieder, F.
Improving Human Decision-Making by Discovering Efficient Strategies for Hierarchical Planning
Tübingen, Germany, The first edition of Life Improvement Science Conference, June 2021 (talk) Accepted

Prentice, M., González Cruz, H., Lieder, F.
Evaluating Life Reflection Techniques to Help People Set Better Value-Driven Life Goals
13th Annual Conference of the Society for the Science of Motivation, Society for the Science of Motivation, 13th Annual Conference of the Society for the Science of Motivation , May 2021 (conference)
Lieder, F., Prentice, M., Corwin-Renner, E.
Toward a Science of Effective Well-Doing
May 2021 (techreport)
González Cruz, H., Prentice, M., Lieder, F.
’What Do You Want in Life and How Can You Get There?’ An Evaluation of a Hierarchical Goal-Setting Chatbot
13th Annual meeting of the Society for the Science of Motivation, Abstract of presentation at the 13th SSM Virtual Congress, Society for the Science of Motivation, Virtual Congress, May 2021 (conference)
Lieder, F., Iwama, G.
Toward a Formal Theory of Proactivity
Cognitive, Affective, & Behavioral Neuroscience, 42(999):999-1000, Springer, March 2021 (article)
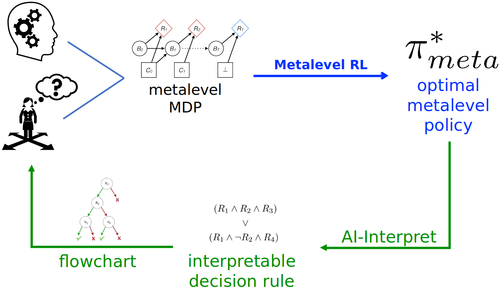
Skirzyński, J., Becker, F., Lieder, F.
Automatic Discovery of Interpretable Planning Strategies
Machine Learning, 2021 (article)
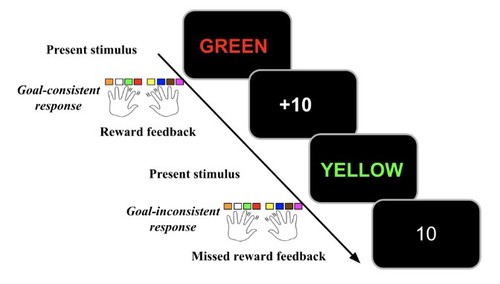
Bustamante, L., Lieder, F., Musslick, S., Shenhav, A., Cohen, J.
Learning to Overexert Cognitive Control in a Stroop Task
Cognitive, Affective, & Behavioral Neuroscience, January 2021, Laura Bustamante and Falk Lieder contributed equally to this publication. (article)
Brohmer, H., Eckerstorfer, L. V., van Aert, R. C., Corcoran, K.
Do Behavioral Observations Make People Catch the Goal? A Meta-Analysis on Goal Contagion
International Review of Social Psychology , 34(1):3, Online, January 2021 (article)
Iwama, G., Weber, F., Prentice, M., Lieder, F.
Development and Validation of a Goal Characteristics Questionnaire
Collabra Psychology, 2021 (article) Submitted
Consul, S., Stojcheski, J., Felso, V., Lieder, F.
Optimal To-Do List Gamification for Long Term Planning
arXiv preprint arXiv:2109.06505, 2021 (techreport)
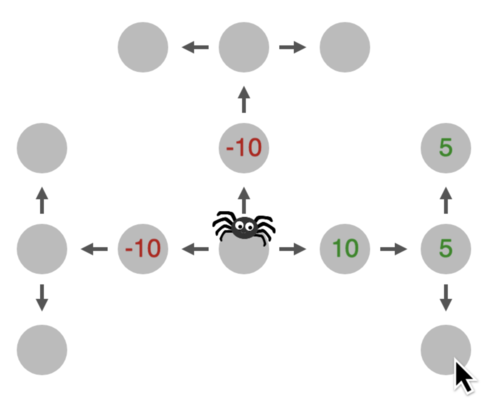
He, R., Jain, Y. R., Lieder, F.
Measuring and modelling how people learn how to plan and how people adapt their planning strategies the to structure of the environment
International Conference on Cognitive Modeling, International Conference on Cognitive Modeling, 2021 (conference)
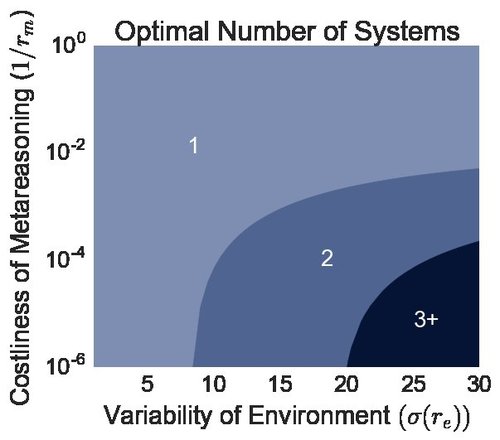
Milli, S., Lieder, F., Griffiths, T. L.
A Rational Reinterpretation of Dual Process Theories
Cognition, 2021 (article)
2020
Kemtur, A., Jain, Y. R., Mehta, A., Callaway, F., Consul, S., Stojcheski, J., Lieder, F.
Improving Human Decision-Making using Metalevel-RL and Bayesian Inference
NeurIPS Workshop on Challenges for Real-World RL, December 2020 (article) Accepted
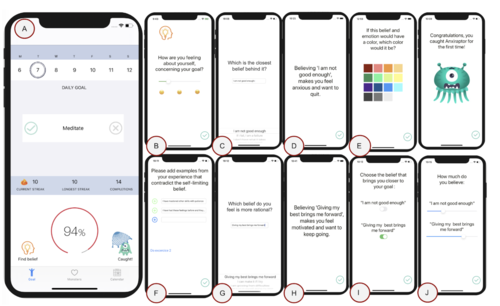
Amo, V., Lieder, F.
A Gamified App that Helps People Overcome Self-Limiting Beliefs by Promoting Metacognition
SIG 8 Meets SIG 16, SIG 8 Meets SIG 16, September 2020 (conference) Accepted
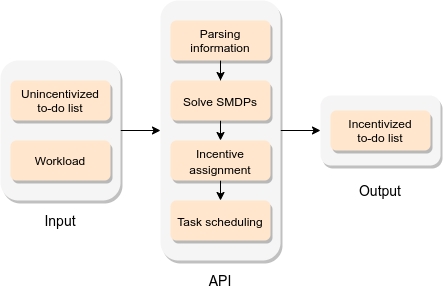
Stojcheski, J., Felso, V., Lieder, F.
Optimal To-Do List Gamification
ArXiv Preprint, 2020 (techreport)
Wirzberger, M., Lado, A., Eckerstorfer, L., Oreshnikov, I., Passy, J., Stock, A., Shenhav, A., Lieder, F.
How to navigate everyday distractions: Leveraging optimal feedback to train attention control
Proceedings of the 42nd Annual Meeting of the Cognitive Science Society, Cognitive Science Society, July 2020 (conference)
Felso, V., Jain, Y. R., Lieder, F.
Measuring the Costs of Planning
Proceedings of the 42nd Annual Meeting of the Cognitive Science Society, (Editors: S. Denison and M. Mack and Y. Zu and B. C. Armstrong), Cognitive Science Society, CogSci 2020, July 2020 (conference) Accepted
Kemtur, A., Jain, Y. R., Mehta, A., Callaway, F., Consul, S., Stojcheski, J., Lieder, F.
Leveraging Machine Learning to Automatically Derive Robust Planning Strategies from Biased Models of the Environment
Proceedings of the 42nd Annual Meeting of the Cognitive Science Society, Cognitive Science Society, CogSci 2020, July 2020, Anirudha Kemtur and Yash Raj Jain contributed equally to this publication. (conference)